[논문 리뷰] Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
지난 번 포스팅에 이어서 이번에도 controllable face generation에 관련된 논문을 소개하려 합니다. 이번 모델 역시 OmniAvatar나 AniFaceGAN과 유사하게 3DMM parameter를 활용하여 표정과 움직임을 세세하게 조정할 수 있는 것이 특징입니다. 이러한 종류의 모델들이 그렇듯, 핵심은 implicit volume representation이 가지고 있는 flexibility, 즉 머리카락이나 장신구 등을 표현할 수 있는 능력과 mesh-guided explicit deformation이 가지고 있는 미세한 표정 및 포즈 조정 능력을 정교하게 잘 조합하는 것입니다. Next3D는 이 둘을 잘 합칠 수 있는 Generative Texture-Rasterized Triplanes라는 representation 방식을 제안합니다.

Next3D
Next3D의 구조는 아래와 같습니다. 이 중에서 특히 흥미로운 부분은 Generative Texture-Rasterized Triplanes, mouth syntesis, 그리고 static component를 위한 tri-plane branch 정도 였습니다. 각각의 역할이 무엇인지 알아보도록 하겠습니다.
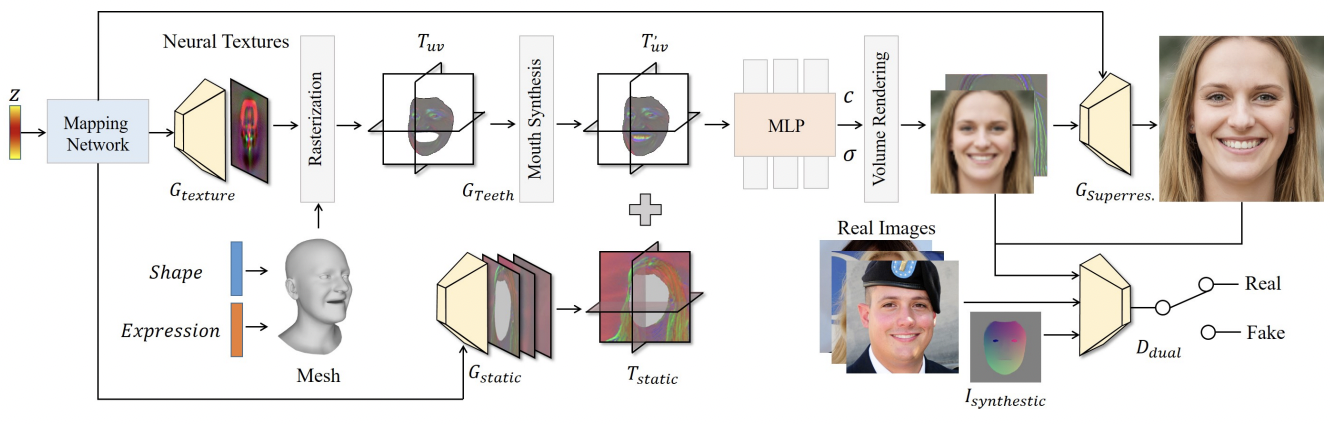
Generative Texture-Rasterized Triplanes
OmniAvatar에서 FLAME의 deformation을 모방한 network를 학습한 것이 흥미롭다고 얘기했었습니다. 그런데 Next3D는 여기서 한 발 더 나아가서, FLAME의 deformation을 직접 가져다 쓰는 방법을 고안합니다. 바로 FLAME의 deformation 정보를 담고 있는 tri-plane을 만드는 것입니다. 이 작업을 어떻게 진행하는지 한 번 천천히 살펴보겠습니다.
Neural Texture
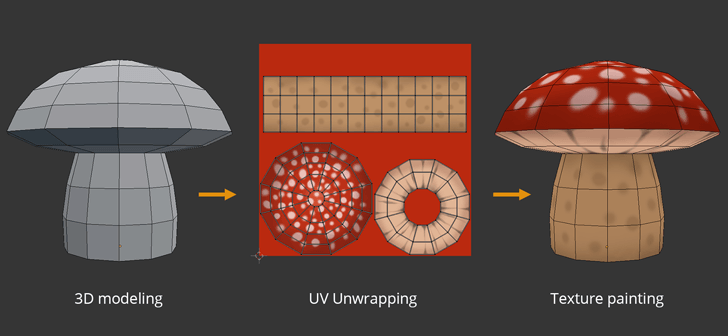
3D mesh 자체는 공간에 대한 정보만 있을 뿐, 우리가 생각하는 색감이나 질감을 갖추고 있진 않습니다. 그래서 mesh를 활용하여 물체를 디자인하는 그래픽 분야에서는 UV texture를 mesh에 ‘씌워주는’, UV wrapping이 널리 활용됩니다. 아래 그림처럼, 우리는 하나의 mesh와 이에 해당하는 전개도인 UV texture를 얻을 수 있습니다. 이 방법론은 FLAME을 기반으로 한 얼굴 생성 모델에서도 많이 활용되는데, DECA와 EMOCA 논문에서도 찾아볼 수 있습니다.
즉, UV mapping은 mesh 위의 점들 각각에 대응하는 3-channel RGB 값을 할당해주는 과정이라 할 수 있겠습니다. 그렇다면 이 때 RGB 값이 아닌, 보다 높은 dimension의 feature를 할당해주면 어떨까요? 이 개념이 바로 Neural Texture의 개념인데, Next3D에서는 texture network $G_{texture}$를 활용하여 RGB 값이 아니라 각 mesh 위의 점들에 32-dimension feature를 할당해줍니다. 이렇게 하면 FLAME을 활용해 mesh를 deform할 때, 즉 표정이나 포즈를 입혀줄 때, neural texture가 이를 그대로 따라가게 됩니다. 즉, AnifaceGAN이나 OmniAvatar에서 하듯 elaborate imitation learning을 할 필요가 없어집니다.
Rasterizing Texture
그러나 이러한 deformation은 한 가지 큰 문제가 있습니다. 바로 surface 위의 지점 외에는 deformation이 정의되지 않는다는 점입니다. 이러한 문제를 Anim-NeRF나 SCARF 등의 전신 생성 모델에서는 neighborhood vertex들의 weighted LBS weight를 통해 풀었으나, 이는 inference 시 시간이 오래 걸려서인지 얼굴 domain에서는 잘 쓰지 않는 방식입니다. Next3D는 여기서 texture rasterizing이라는, 그래픽 분야에서 쓰이는 방법론을 활용합니다. 우선, 우리는 얻어진 neural texture $T$를 FLAME을 통해 추출된 template mesh에 입혀줍니다. 원래대로라면 각 FLAME의 vertex에 3-channel RGB 값이 할당되겠지만, 우리는 $T$를 통해 UV wrapping을 진행했기 때문에 각 vertex는 32차원의 neural texture를 할당받게 됩니다. 이를 바라보는 방향에 따라 평면화를 진행하는 것이 neural texture rasterizing이라 이해하시면 되겠습니다.
그러나 이를 활용한 deformation은 surface 위 점들에 대한 위치만을 deform해줍니다. 그러나 우리는 surface 위가 아닌, 공간 내 모든 점들에 대한 deformation이 필요합니다. 저자들은 여기서 tri-plane 표현형을 활용합니다. Neural texture가 바라보는 방향에 따라서 그 표현형이 달라짐을 활용하는 것입니다. 우리는 xy, yz, zx 각 평면에 수직하는 방향의 view direction을 활용한 rasterization을 통해 각 plane을 얻어냅니다. ($256\times256\times32$ 차원) 이를 통해, 우리는 imitative learning을 거치지 않고도 mesh의 deformation을 모방할 수 있는 tri-plane 표현형을 얻을 수 있게 됩니다.
Mouth Syntehsis Module
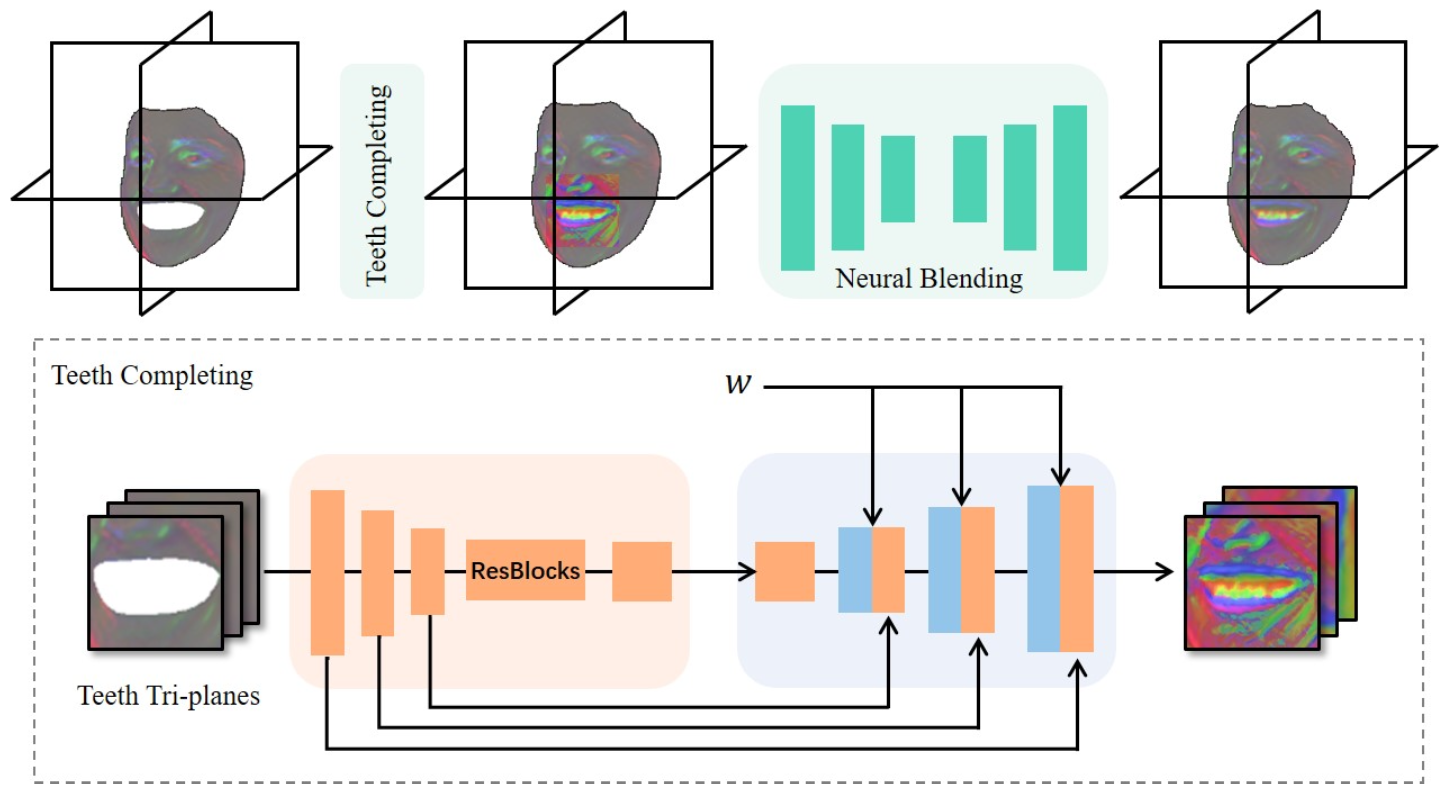
FLAME의 한계점 중 하나는 치아 부분에 해당하는 mesh가 존재하지 않는다는 점입니다. 따라서 Next3D는 이를 보완하기 위해 teeth synthesis module $G_{teeth}$을 도입합니다. 우선, landmark를 활용해서 입 주변의 tri-plane 정보를 얻어내고, 이를 $64\times64$ 크기로 resize 해줍니다. 이렇게 얻어진 teeth의 feature $f_{teeth}$는 style-modulated UNet 구조의 입력으로 활용되어, 위 그림처럼 치아에 대한 정보가 입혀진 같은 차원의 feature $f\prime_{teeth}$ 으로 출력됩니다. 이는 원래의 Tri-plane $T_{uv}$에 concat 됩니다. 이 때, 경계 부분의 부자연스러움을 해결하기 위해 shallow-UNet-based neural blending module에 $T_{uv}$를 통과시켜서 새로운 tri-plane $T\prime_{uv}$를 얻어냅니다. 이를 활용하여 이미지를 합성하면, FLAME mesh를 활용했음에도 치아 부분을 잘 생성하는 것을 확인할 수 있습니다.
Modeling Static Components
얼굴의 요소 중에서는 FLAME의 deformation에 영향을 받지 않는 부분도 있습니다. 예를 들면, 머리카락이나 안경, 배경 부분은 FLAME의 deformation에 영향을 받지 않습니다. 이러한 요소들은 neural texture를 통해 deformation될 필요가 없기 때문에 별도의 tri-plane인 $T_{static}$을 통해 인코딩합니다. 이는 facial animation 생성 시 consistency를 유지하는 데에 도움을 준다고 합니다.
Experimental Results

생성된 결과만 보면 굉장히 좋은 생성 퀄리티를 보입니다. FLAME parameter를 통해 feature control이 가능한 결과물이라는 것을 감안하면, 좋은 성능을 보이고 있음을 알 수 있습니다. 그리고, Pivotal Tuning Inversion를 활용하여 아래와 같이 실존 인물을 기반으로도 controllable face generation이 가능하다고 합니다.

Neural Texture를 활용한 deformation이라는 아이디어와, controllable한 얼굴을 만들어내면서도 좋은 image quality를 유지한다는 점에서 Next3D는 매우 흥미로운 논문이었습니다. Unconditional controllable 3D face generation의 경우, 아직 inversion 모델이 없을 거라 생각했는데 Pivotal Tuning을 활용해서 이미 어느 정도의 성능을 확보했다는 점도 흥미로웠습니다. 프로젝트 페이지에서 보니 아직 영상 레벨에서의 부자연스러움 등이 남아있긴 한데, 이러한 것들을 고도화하는 것도 재미있는 후속 연구가 될 것이라 생각되네요.