[Paper Review] OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis
최근 controllable face video generation 관련 논문이 조금씩 등장하고 있습니다. 이들은 FLAME 등 고전적인 3DMM 기반의 morphable face model(이것도 언젠가 시간이 되면 다루겠습니다)과 NeRF를 결합하여 표정과 얼굴 각도 등을 세밀하게 조정할 수 있도록 합니다. 사실 SMPL, FLAME 등의 통계 기반 모델링은 비교적 예전부터 존재했습니다. 그러나 이들이 얼굴(또는 몸)의 움직임을 disentangle하게 조정할 수 있다는 큰 장점을 가지고 있었음에도, 피부 질감을 반영하여 mesh에 색을 어떻게 입힐지, 머리카락은 어떻게 모델링할지 등의 한계점으로 인해 face video generation 분야에서는 적극적으로 쓰이지 않아 왔습니다. 그러나 최근 NeRF의 등장으로 이러한 한계점들을 극복할 수 있는 가능성이 보이면서 이들을 적극적으로 활용하는 모델들이 하나 둘 등장하고 있습니다. 오늘은 그 중에서도 CVPR2023에 발표된 OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis를 다뤄보려 합니다. 개인적으로 재미있는 아이디어들이 많아서 흥미로웠던 논문이었습니다.

Controllable Face Generation
EG3D, GRAM 등 3D 기반 unconditional generation 연구들이 활발하게 이뤄지고 있고, 준수한 성능을 보이면서 큰 화제가 되고 있습니다. 그러나 이들은 카메라 각도 외에 사람의 생김새, 얼굴 표정 등을 조절할 수 없다는 한계점을 안고 있습니다. OmniAvatar는 이러한 한계점을 극복하기 위해서 FLAME의 framework를 차용합니다. 즉, NeRF를 활용하여 FLAME의 parameter들로 만들어진 geometry를 재현한다고 이해하면 될 거 같습니다. 저자들은 semantic signed distance funcion(SDF) 이라는 새로운 개념을 통해서 observation space와 canonical space 사이의 volumetric correspondence map을 정의한다고 합니다. 즉, semantic SDF를 통해 FLAME의 head geometry의 재구성 뿐만 아니라, pose와 expression parameter를 통한 deformation까지도 수행할 수 있다는 점입니다. 사실 AniFaceGAN을 읽으며 implicit neural representation을 통해 statiscal modeling의 geometry를 모방한다는 것도 신기했는데, 아예 volumetirc correspondence map까지 만들 수 있다는 점이 대단하네요.
** Volume density 대신 SDF를 쓰는 이유
> NeRF에서 주로 활용하는 volume density field의 경우 3D geometry에 대해서 충분한 constraint를 갖지 못하기 때문에, surface reconstruction 시 굉장히 noisy한 결과를 만들어낸다고 합니다. Semantic SDF의 경우 color를 추정하는 것이 아니라, 오롯이 geometry를 추정하는 것이 목적이기 때문에 noisy해질 수 있는 volume density가 아니라 SDF를 활용하지 않았을까 싶은 개인적인 추측이 듭니다. 보다 자세한 내용이 궁금하신 분은 NeurIPS2021에 발표된 논문 NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction를 읽어보시면 도움이 될 듯 합니다.OmniAvatar
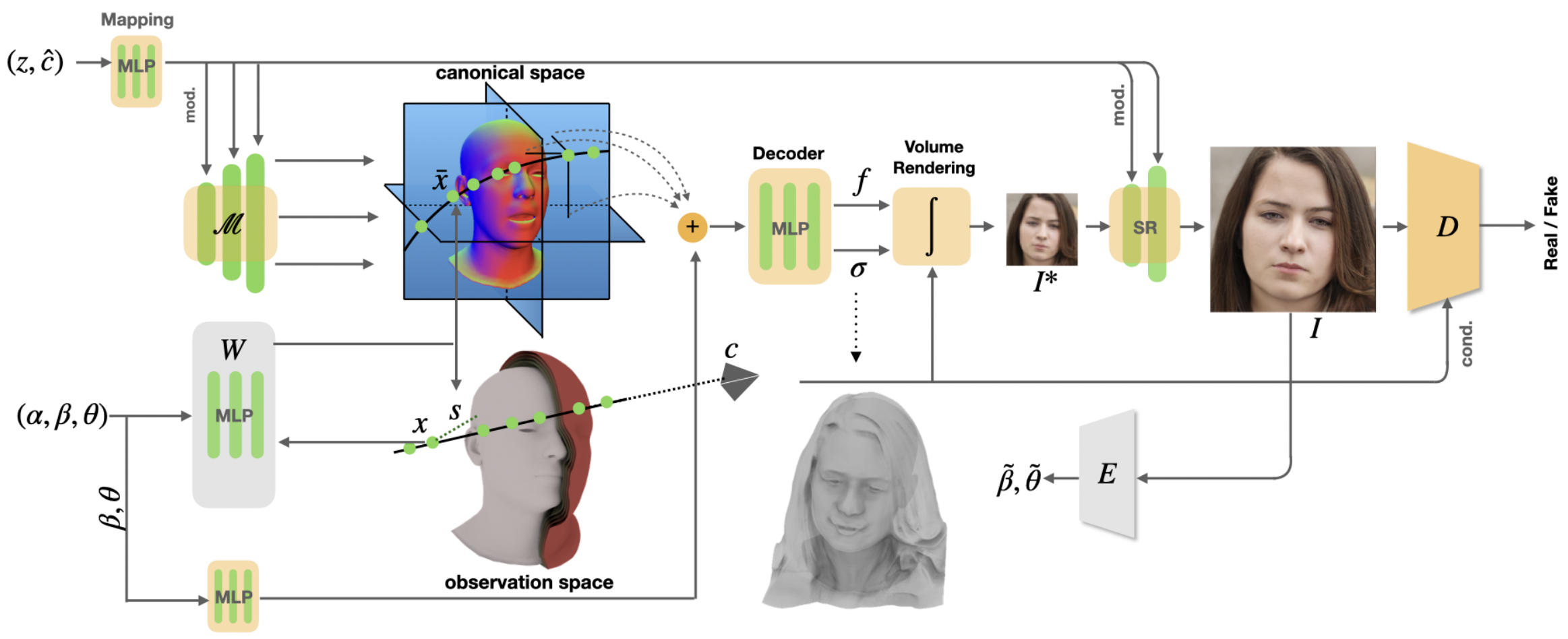
OmniAvatar의 전체적인 구조는 위와 같습니다. Generator $G$는 Gaussian 분포로부터 샘플링 된 $z$, camera pose $c$, 그리고 FLAME 기반 shape parameter $\alpha$, expression parameter $\beta$, pose parameter $\theta$(이들을 묶어서 $p=(\alpha, \beta, \theta)$로 표현합니다)를 입력으로 받아서, FLAME parameter의 geometry에 맞는 photo-realistic human head image $I_{RGB}(z|c,p)$를 만들게 됩니다. 이 과정은 두 단계로 이루어지게 됩니다.
Deformable Semantic SDF
Semantic SDF $W$는 앞서 언급했듯, 단순히 FLAME의 geometry를 reconstruct하는 것에서 그치지 않고, observation space와 canonical space 사이의 volumetric correspondence를 mapping하는 것이 그 목적입니다. $W$는 FLAME parameter $p$를 기반으로 하는 observation space $\mathcal{O}(p)$ 상의 $x$와 를 입력으로 받아 canonical space $\mathcal{C}(p)$ 상의 3D correspondence인 $\bar{x}$와 FLAME mesh surface $S(p)$까지의 가장 가까운 signed distance (SDF의 정의 참고) $s(x|p)$를 return 합니다. 이를 정리해서 나타내면 아래와 같습니다.
$W$는 surface 위에서 sampling된 점들로 만든 batch $N$과, surface 위가 아닌 부분에서 sampling된 점들로 만든 batch $F$를 각각 만들고, 아래와 같은 세 개의 loss term을 통해서 학습됩니다.
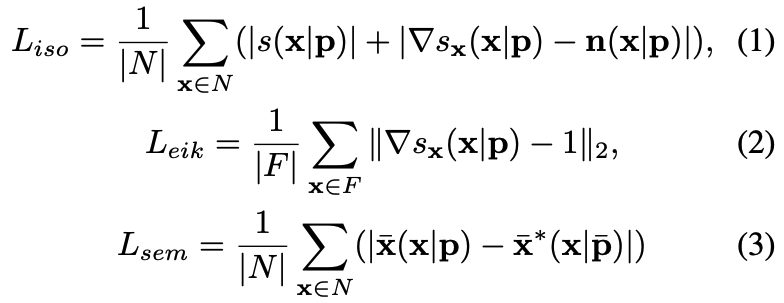
먼저 $L_{iso}$는 surface 위에서의 signed distance 값 $s(x|p)$가 0이 되도록 하고, 이 값의 gradient $\nabla s_x(x|p)$가 표면에서의 normal 값과 같아지도록 학습시키는 loss입니다. 그 다음 Eikonal loss $L_{eik}$는 SDF의 gradient norm이 1이 되도록, 즉 Eikonal 방정식을 만족시키게 하는 loss입니다. 사실 수식상에서 $||\nabla s_{x}(x|p)-1||$ 가 아니라 $(||\nabla s_{x}(x|p)||-1)^2$로 표기되는 게 맞는 거 같은데, 혹시라도 제가 잘못 생각하고 있는 거라면 알려주세요.
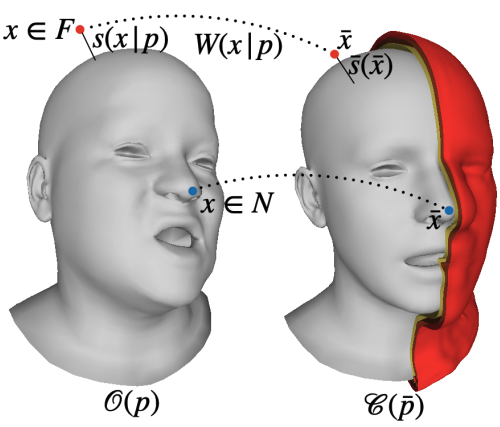
가장 신기했던(?) loss는 semantic loss $L_{sem}$이었습니다. $L_{sem}$이 바로 volumetric correspondence가 잘 학습되도록 도와주는 loss인데, surface 위 sample $x$가 canonical surface 위의 ground-truth correspondence $\bar{x}^*$로 mapping될 수 있게 도와주는 함수입니다. 이 때 $\bar{x}^*$는 $x$와 같은 barycentric coordinates를 가지고 있는 점입니다. $\bar{x}^*$가 어떻게 ground truth가 되는지가 궁금하다면 Generalized Barycentric Coordinates for Mesh deformation를 참고하시길 바랍니다. 사실 간단하게는 signed distance, 즉 $||s(\bar{x}|\bar{p})-s(x|p)||$를 minimize하는 loss를 생각해볼 수도 있습니다. 그러나 같은 signed distance를 가지는 점이 무수히 많다는 점을 생각해보면, signed distance만을 regularize하는 loss는 충분하지 않다고 합니다.
$W$는 large corpus of 3D FLAME로 미리 training 해둔다고 합니다.
3D-Aware GAN
이제 $W$를 통해서 observation space에서의 $x$를 canonical space $\bar{x}$로 mapping하는 함수는 익혔습니다. 이제 이 위에서 rendering만 하면 되는데, 우리는 만들어진 얼굴의 형상이 canonicalized FLAME parameter $\bar{p}$가 만들어낸 mesh와 geometry가 최대한 유사하기를 바랍니다. 앞에서 $W$를 통해서 열심히 deformation까지 해뒀는데, 정작 Volume Rendering을 하고 나니 완전히 다른 모양의 얼굴이 나오면 속상하지 않을까요? 이를 방지하기 위해서 우리는 volume rendering에서의 출력값 volume density $\sigma$에 대해서 아래와 같은 loss를 걸어줍니다.
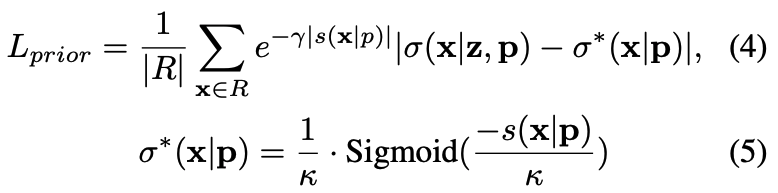
FLAME parameter의 geometric prior를 따르라고 해서 prior loss인 거 같습니다. 식이 복잡해보이는데, 사실 굉장히 단순합니다. 우선 volume renderer의 출력값 $\sigma^*(x|z,p)$가 $\sigma^*(x|p)$를 모방하도록 하고 있습니다. $\sigma^*(x|p)$을 설명하는 (5)번 식을 잘 봐봅시다. 우선 $s(x|p)=0$인 경우, $\sigma^*(x|p)$는 $1/2\cdot\kappa$가 됩니다. 이 값이 아마 surface 표면 위에서의 volume density 기준이 될 겁니다. 그리고 $s(x|p)$이 0보다 더 작아지는 경우, 우리는 SDF의 정의에 따라 $x$가 surface 내부로 점점 들어가고 있다고 생각할 수 있습니다. 이 경우 $\sigma^*(x|p)$의 값은 점점 커져서 $1/\kappa$에 수렴하게 됩니다. 반대로 $s(x|p)$이 0보다 더 커지는 경우, 우리는 SDF의 정의에 따라 $x$가 surface에서부터 점점 멀어지고 있다고 볼 수 있습니다. 이 경우 $\sigma^*(x|p)$의 값은 점점 작아져서 $0$에 수렴하게 됩니다. 간단하게, SDF가 정의한 surface의 모양을 volume rendering을 통해서 reconstruct한다고 생각하시면 되겠습니다.
마지막으로, rendering 시에는 surface 표면에서의 값이 계산될 때 가장 중요하기 때문에 양의 방향이든 음의 방향이든 surface에서 멀어지는 점에 대한 계산은 중요도가 떨어지게 됩니다. 그래서 $L_{prior}$의 각 계산항 앞에는 decay term $e^{-\gamma|s(x|p)|}$가 붙습니다. $|s(x|p)|$ 값이 크다는 말은 그만큼 surface에서 멀다는 뜻이므로, 합리적인 decay term이라 생각되네요. 그리고 사실 여기에는 더 큰 이유가 숨어 있는데, 바로 FLAME은 머리카락이나 안경 같은 feature는 모델링하지 못한다는 것입니다. 즉, decay term을 둠으로써 surface에서 비교적 먼 곳에 존재하는 머리카락이나 안경 등은 조금 더 자유롭게 생성할 수 있도록 자유도를 높여줄 수도 있게 됩니다.
아래 그림은 같은 FLAME parameter를 활용하여 다른 이미지들을 만든 결과입니다. 같은 FLAME parameter를 활용했음에도 $L_{prior}$가 없으니 얼굴 형태나 생김새가 많이 달라지는 것을 확인할 수 있습니다. 동시에 full pipeline에서는, 얼굴 형태나 표정은 유지되면서도 머리 스타일, 안경 등의 feature가 자유도 높게 생성되는 것도 신기하네요.

$L_{prior}$를 통해 coarse-level expression은 control할 수 있지만, 눈 깜빡임 같은 detail한 expression까지 control하기는 어렵다고 합니다. 이러한 표정 변화는 이미지 상에서의 변화는 크지만, geometry가 크게 변하는 것은 아니기 때문에 volume density 값을 학습시키는 $L_{prior}$가 감지하기는 어렵기 때문입니다. 또한, 입 주변처럼 근육이 많아서 correspondence가 복잡한 부분은 $L_{prior}$와 같은 point-wise geometric loss만으로 세세한 표정을 감지하기는 어렵다고 합니다. 그래서 이러한 부분은 geometry-level이 아닌 image-level supervision이 유리하게 작용한다고 합니다. 우선적으로 저자들은 학습 이미지와 그에 해당하는 label $p$를 활용하여 이미지를 입력으로 받고, FLAME parameter를 출력하는 encoder $E(I_{RGB})=(\tilde{\beta}, \tilde{\theta})$를 학습합니다. (DECA나 EMOCA 같은 공개된 모델을 활용해도 될 거 같네요) 그리고 여기서 출력된 값을 활용하여 아래와 같은 loss를 걸어줍니다.
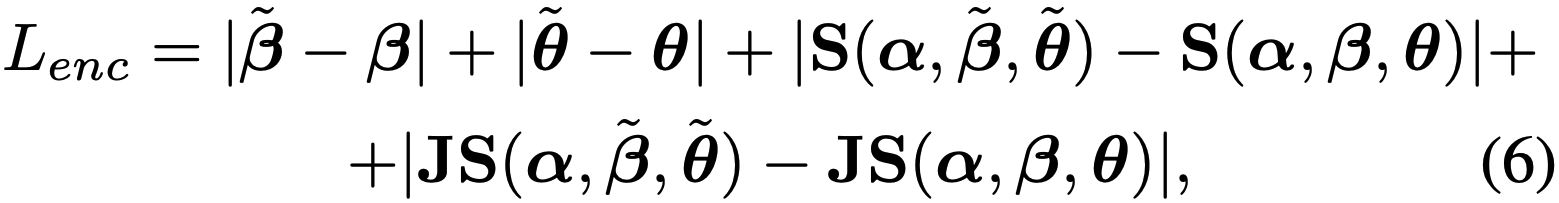
여기서 $S$와 $J$는 각각 FLAME mesh의 vertices, 3D landmark regressor를 의미합니다. 즉, coefficients 사이의 거리와, 구축된 FLAME mesh 사이의 거리, 그리고 구축된 FLAME mesh에서 추출된 landmark 사이의 거리까지, 3중으로 loss를 걸어주는 것입니다. 실제로 아래 그림을 보면, $L_{enc}$가 존재하지 않는 경우, 같은 $p$로 생성된 이미지 사이에서도 표정이 꽤나 달라지는 것을 확인할 수 있습니다.

마지막으로, 저자들은 dynamic하게 변하는 detail에 대해서 더 잘 모델링하기 위해서 MLP-decoder가 $\beta$와 $\theta$를 고려하여 conditional decoding을 하게 formula를 아래와 같이 바꿔줍니다.
Experiments
OmniAvatar는 two-stage로 학습이 이루어집니다. 첫 번째 stage에서는 Gaussian sampling으로 추출한 $p$로 부터 150K개의 FLAME parameter를 만들고, 이를 활용해서 semantic SDF $W$를 학습합니다. 각 mesh에서는 앞서 언급했듯 surface 위에서의 sample와 그렇지 않은 sample을 각각 추출해야 하는데, 저자들은 각각 4K개씩 추출합니다. 이 점들을 활용하여 $W$를 학습하고, 두 번째 stage를 학습할 때에는 freeze해둡니다. 두 번째 stage는 70,000장의 FFHQ로 학습을 진행하고, 각각의 이미지에서 camera pose와 FLAME parameter를 estimate한다고 합니다.
Quantitative comparison은 아래와 같습니다.
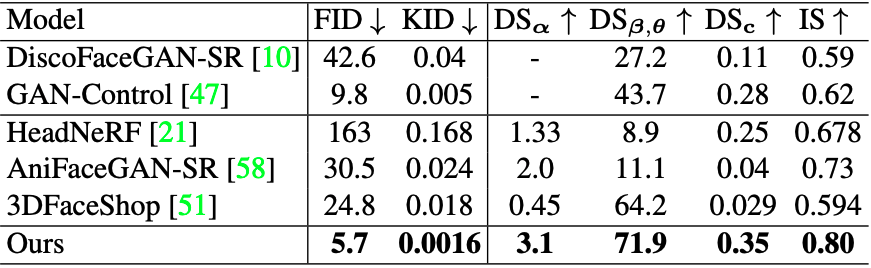
AniFaceGAN을 처음 봤을 때에도 굉장히 신기하고 잘 되는 모델이라 생각했는데, 굉장히 큰 폭으로 이겨버린 느낌이네요. FID가 5.7로 굉장히 낮은 값을 보이고 있습니다. 그 외에도 아래처럼 각 단계별로 mesh가 변해가는 모습도 흥미롭네요.
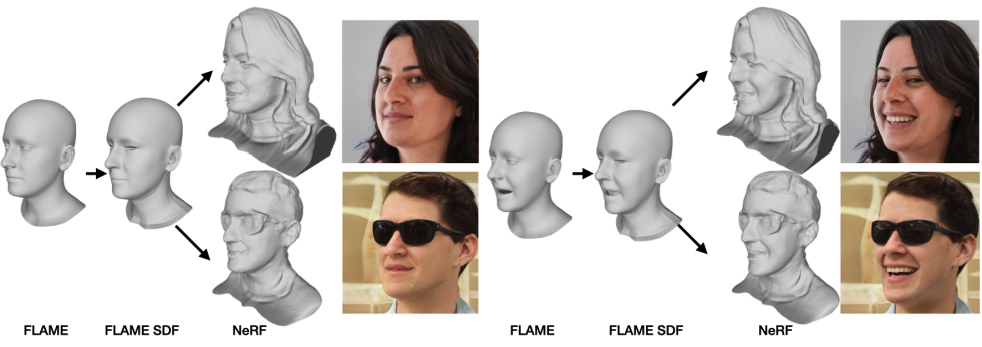
Limitations & Conclusion
그러나 아직까지도 expression이 FLAME space에 굉장히 제한되어 있다고 합니다. 그래서 FLAME에서 잘 표현되지 않는, 입술을 오므리는 표정이나 볼을 부풀리는 표정 등은 잘 합성되지 않는다고 합니다. 또한, gaze control이 부재한 것 역시 한계점으로 언급하고 있습니다. 그리고, face reenactment에 사용되는 가능성에 대해서도 직접 언급하고 있는데, 이는 reference video의 FLAME tracking의 성능에 많이 의존하게 된다고 이야기 하고 있습니다.
그럼에도 controllable한 face generation으로 이 정도 퀄리티를 만들어낸다는 것은 굉장히 흥미로웠습니다. 언급된 limitation들 역시 모델 자체의 한계보다는 FLAME의 표현형, FLAME estimation network의 한계라는 느낌이 더 강했던 거 같습니다 일부러 그런 한계점만 언급한 걸지도 모르지만 말입니다 개인적으로 implicit neural representation으로 FLAME이나 SMPL같은 statistical modeling의 mesh와 linear blend skinning 기반 deformation을 모방하는 것이 불가능할 것이라 생각했었습니다. 그러나 그렇지 않다는 연구가 하나 둘 나오고 있는 거 같네요. Statistical modeling과 implicit neural representation을 어떻게 더 잘 결합해볼지 더욱 더 생각해봐야겠습니다. 긴 글 읽어주셔서 감사합니다.